
The symptom
The model writes the file. The tool rejects it.
The big brain in Jarvis v2 just spent a turn generating 7,146 characters of CSS. It fired a write_file call at the executor. The tool came back with:
write_file rejected: path is required. Your last call had 7146 chars of content but no path field.
The model retried. Same 7,000-character payload. Same error.
Third retry. Same thing.
The content was perfect. The destination was missing.
Why it happens
Small models are JSON-fragile at long lengths.
A frontier model with hundreds of billions of parameters will hand you a well-formed tool call at any payload size. A 26B model running locally is doing the same job with a fraction of the machinery, and the edges show up under load.
The specific failure: the model's JSON output drops or truncates a field near a long string. The content field survives because it's the thing the model is focused on. The path field is short and sits at the edge, so when a stray character or an unbalanced quote knocks the serializer off course, the path comes out empty.
Pattern match from the Jarvis observer log across April 17 and 18: 16 failures with the same empty-path signature, all of them payloads between 5,677 and 8,281 characters. Not occasional. Systematic at scale.
It's one shape of a broader pattern the community's started calling context rot, which I'll come back to below.
The wrong fixes
You can't system-prompt your way out of a small model's JSON limits.
First instinct was to tighten the system prompt. Give the model an example. Tell it to always include the path. Write it in capitals.
None of it landed. The model was never deciding to drop the path. It was losing a character of JSON syntax somewhere in the emission, and by the time the parser hit the path field, the value was an empty string.
Second instinct was a stricter tool schema. Mark path as required. Make the failure louder. That's already happening, and the quoted error is the schema doing exactly that. Still no file.
Third instinct was retry with feedback. Sometimes works. But small models can reproduce the same bad output run after run, and the retry loop carries a hidden cost.
The hidden cost
Failed tool calls don't just fail. They eat the window.
Every tool call stays in the conversation history, pass or fail. When the model's rejected write_file call carries 7,000 characters of content, that 7,000 characters stays in the context even though the tool wrote nothing.
Do it twice and you've got 14,000+ tokens of failed attempts sitting in the window.
On a 32K local context, that's nearly half the window spent on writes that never landed. The model's next turn is working with half as much room to actually think, and the attempt it produces is often worse because the window is now cluttered with its own bad outputs.
The compounding is the real problem. Quality degrades because the context is polluted with noise. And the model has less space to produce a corrected call because the failures already filled the room. Recovery pays off twice. The file gets written, and the window stays clean.
Context rot
This isn't just a local-model quirk.
Chroma's Context Rot research (Hong, Troynikov, Huber, July 2025) tested 18 frontier models and found every single one degrades as input length grows. A U-shaped curve: information near the start and end of the window holds up fine, but accuracy on anything in the middle drops 30%+ once the context fills.
Failed tool calls in conversation history are exactly the kind of structured noise that pulls those numbers down. Counterintuitively, the research also shows coherent text degrades the window faster than shuffled text, because coherent sequences create stronger recency bias for attention to contend with.
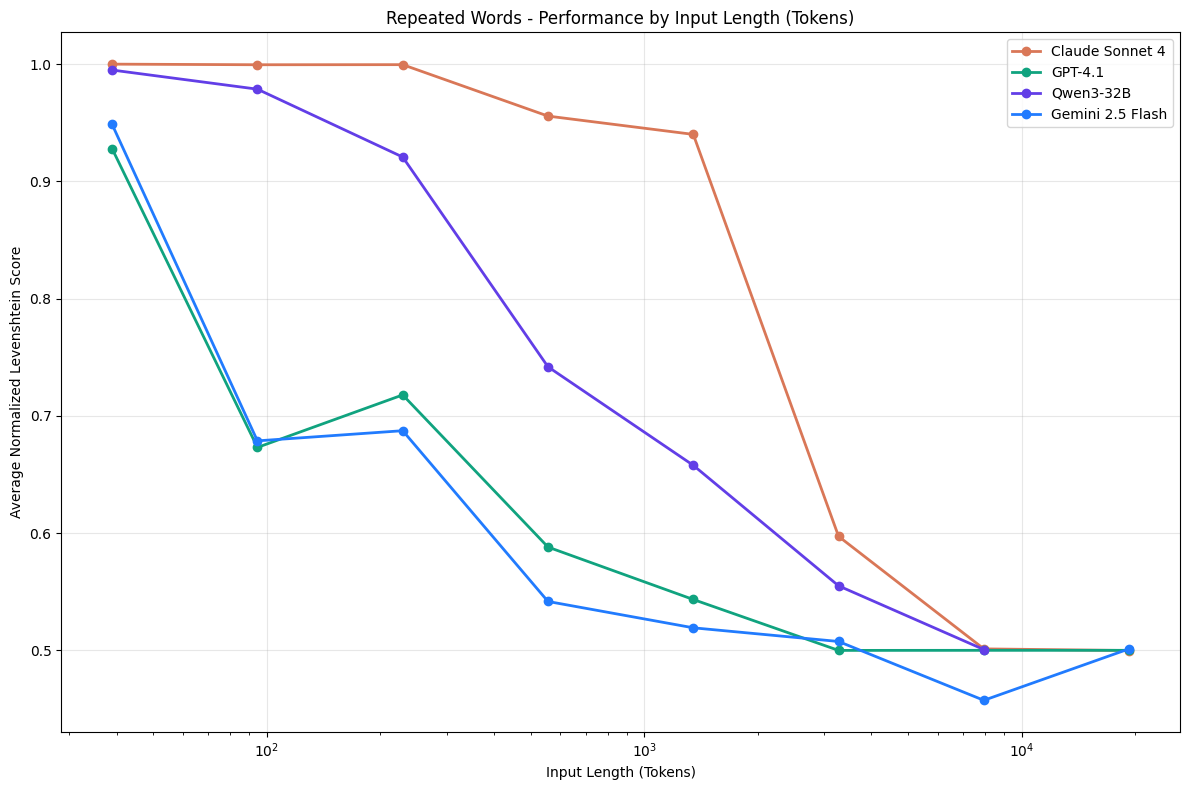
Every model tested degrades as context fills. Chart from Chroma's Context Rot research (July 2025). Used with attribution.
The real fix
Classify the content and rescue the write.
The recovery layer sits between the model's tool call and the filesystem. When write_file arrives with content but no path, it runs three steps instead of returning an error.
Sniff. Look at the first few hundred characters of the content. HTML has <!DOCTYPE or <html>. CSS has :root { or a leading comment like /* header.css */. JavaScript has import, function, or const. Markdown leads with headers and prose. Every file type has a signature you can match in a handful of bytes.
Classify. Apply routing rules. For an HTML page, the first one in the session gets index.html and subsequent pages slug their filename from the <title> tag. A CSS file with a leading comment uses that comment's name. Otherwise it's styles.css. Scripts get script.js. If nothing classifies cleanly, the content goes to workspace/<project>/.rescued/write_<stamp>.<ext> so the model's retry has something to reference instead of guessing in the dark.
Write. The file lands on disk. The model's next turn sees the listing and moves on with the task.
The code for this lives in jarvis/core/big_brain.py as _rescue_missing_path() (with a few helpers around content sniffing and filename suggestion). Every recovery emits a path_rescued event in the observer log with the reason, the tool name, and the character count preserved, so I can audit after the fact which writes were saved by the classifier versus the model.

Same broken tool call, two outcomes. The recovery layer is the difference between three rejected retries and a file on disk.
The evidence
16 failures across two days. Zero lost files.
Since the recovery layer went in, every empty-path write_file call on Jarvis v2 has either landed at an inferred path or stashed safely in .rescued/. Across two working days of real task traffic: 16 failures caught, 16 writes saved, with content sizes ranging from 5,677 to 8,281 characters.
Before recovery, those 16 failures burned roughly 70,000 tokens retrying the same broken JSON. Now it costs about 50 tokens per recovery, and the task finishes.
Exacting inputs are a hardware-level expectation. At 26B parameters the model can't always meet them. So the environment does.
The takeaway
Small local models need environmental support.
A frontier model can muscle through a sloppy tool contract. A small local model hits the edges of that contract constantly, and no amount of prompting reaches the part that's actually breaking. The model isn't ignoring the rule. It's losing a character of JSON somewhere in the stream.
The move that works: if the failure is predictable, don't ask the model to solve it. Build the solution into the environment.
For write_file that means sniff the content, pick a reasonable name, and save the work. For other tools it's going to mean something else. But the principle is the same. When a small model is reliable at the thing it's good at and unreliable at the thing surrounding it, wrap the unreliable part. Let the model do what it's good at. Give it a hand on the rest.
And remember: context rot isn't only a small-model problem. Every frontier model degrades with longer context; small ones just hit the wall sooner. Whatever you're building, the tool contract you write today is the context someone's working with tomorrow.
Further reading
Where this thinking came from.
The context-rot framing is from Chroma's research team (Kelly Hong, Anton Troynikov, Jeff Huber, July 2025). It's the clearest summary I've read of how and why LLM performance degrades as context grows.
- Context Rot: How Increasing Input Tokens Impacts LLM Performance: the paper
- chroma-core/context-rot: the replication toolkit
- P6: Context Rot: Hamel Husain's shorter writeup, good if you want the 5-minute version
Share this post
Keep reading
More worth your time

Blog post · AI, Building, Process
The Context Window Is a Trap
We chased million-token context windows for years. The rot didn't get fixed. It just moved somewhere quieter.
Read post →
Blog post · AI, Building, Process
The bottom-up edit rule
When a model queues five edits against one file, working top-down is a bug. Here's the order that fixed it.
Read post →Stay in the loop
New posts, same voice.
Get a short email when I publish something new. No weekly digests, no link dumps — just the essays.